Java中算法所用语法总结
基本输入输出
1 | // 基本输入 |
大整数与高精度
大整数
1 | import java.math.BigInteger; |
高精度
1 | BigDecimal add(BigDecimal other) |
String, StringBuilder
String
1 | // String |
StringBuilder
1 | // StringBuilder |
进制转换
1 | String s = Integer.toString(a, x); //把int型数据转换乘X进制数并转换成string型 |
排序
1 | Arrays.sort(int[] a, int fromIndex, int toIndex) |
C++中的容器在Java中的用法
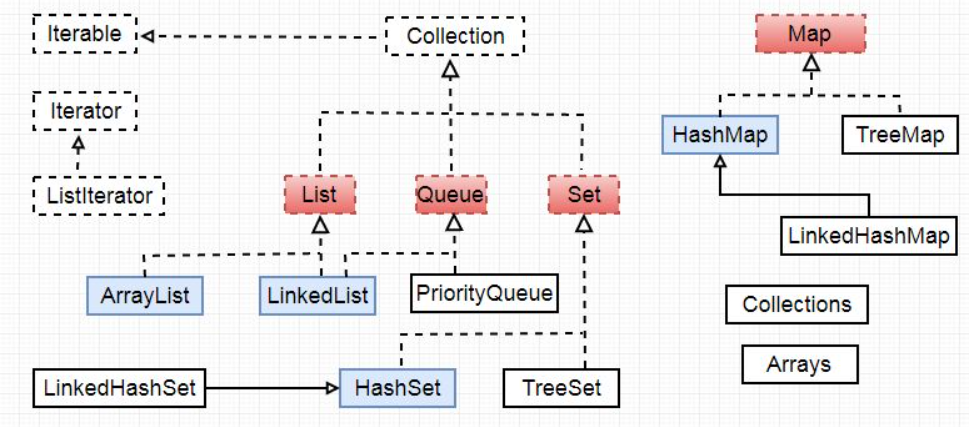
| C++ | Java | 说明 |
|---|---|---|
| vector | ArrayList | 可变长度数组 |
| list | LinkList | 链表 |
| deque | ArrayDeque | 双端队列 |
| stack | Stack | 栈 |
| queue | Queue | 队列 |
| priority_queue | PriorityQueue | 支持优先队列 |
| set | TreeSet | 集合、数据有序、二叉搜索树实现 |
| unordered_set | HashSet | 哈希表组织的set |
| LinkedHashSet | 按插入有序,支持哈希查找 | |
| map | TreeMap | 键值对映射,按key有序 |
| unordered_map | HashMap | hash组织的map |
| LinkedHashMap | 按插入有序,支持哈希查找 |
Vector -> ArrayList
- 可调整大小的数组的实现
List接口。
1 | // 返回此列表中的元素数。 |
list -> LinkedList
- 用法基本同ArrayList, 但底层实现为链表
ArrayDeque
-
可以用此数据结构实现栈、队列和双端队列
-
不允许null元素
1 | // 当作为栈的时候 |
PriorityQueue
-
基于优先级堆的无限优先级queue。
-
不允许null元素
-
小顶堆
1 | // 优先队列举例 |
迭代器
1 | Collection<Integer> c = new Collection<>(); |
HashSet & TreeSet
-
不会存储重复的元素
-
TreeSet 保证集合有序,基于红黑树。而HashSet 基于哈希表实现。
1 | // TreeSet |
HashMap & TreeMap
-
键值对
-
Map是java中的接口,Map.Entry是Map的一个内部接口。
-
由于Map中没有实现Iterator接口,故需要转化为set类型,用entrySet()方法。
-
TreeSet不允许有重复的Key,重复put只会覆盖上一个值
1 | Map<String, String> map = new HashMap<String, String>(); |
1 | // LeetCode 347 返回前K高频元素 |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 AFlyingSheep's Blog!

评论