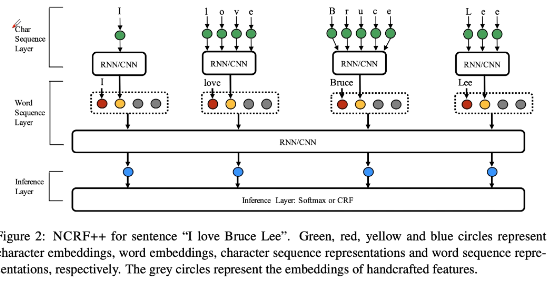
实体抽取——BiLSTM-CRF模型
BiLSTM-CRF模型
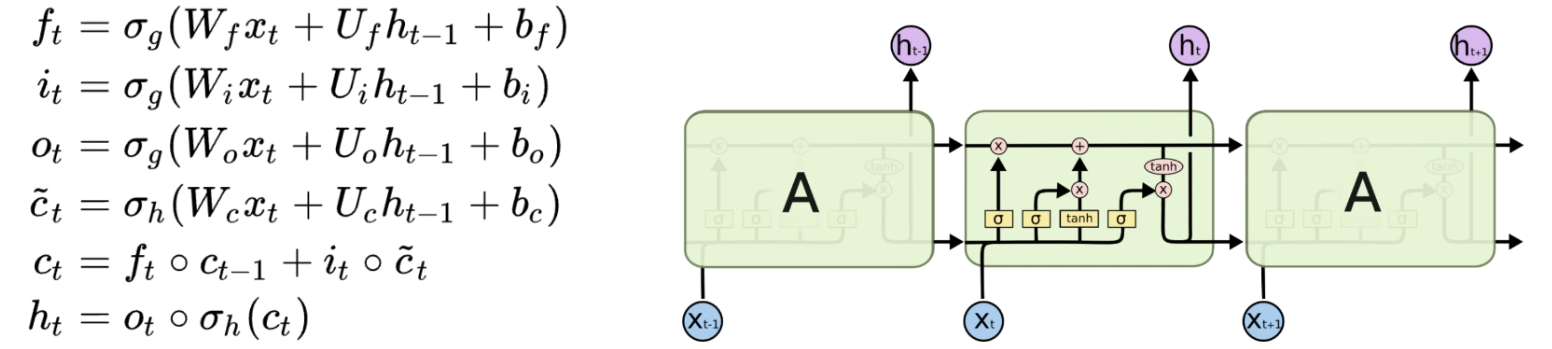
在自然语言处理中,很多任务都涉及到序列标注,比如词性标注、分词、命名实体识别等,这些任务都有一个特点是输入序列和标签序列是等长的,因此,常用的解决方法有HMM、MEMM、CRF等,本文将介绍一个2015年提出来的非常经典模型,即BILSTM-CRF模型,该模型现在已经成为命名实体识别、词性标注、分词等任务的主流模型。
BiLSTM-CRF模型结构
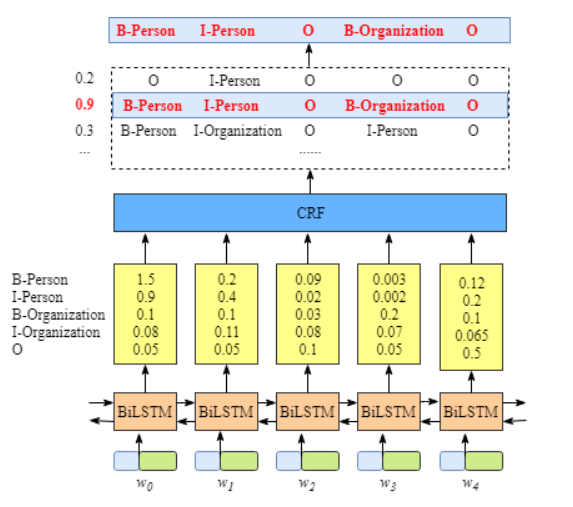
- 句中转化为字词向量序列,可以事先训练好或者随机初始化。可以使用Model-Base
- 经过BiLSTM特征提取,输出是每个单词对应的预测标签
- 经过CRF层的约束,输出最优标签。
Word Embedding
流程
- 将一个含有n个词的句子记为:x = (x1, x2, …… , xn)
- 利用预训练的embedding矩阵将每个字映射为低维稠密向量。
BiSTEM提取文本特征
流程:
- 将每个句子的Embedding序列作为双向LSTM各个时间步的输入
- 将正反输出的隐状态进行拼接,得到完整的隐状态序列。
理解:
- 为什么NER选择的神经网络从RNN演变为LSTM,再到BiLSTM?
- RNN被赋予对于前面内容的“记忆”能力。
- 问题:总长度为T的RNN公式展开后发现,网络深导致梯度消失与梯度爆炸(每一个输入依赖于输出)。
- LSTM引入门机制,每个t时刻都选择性地改变记忆,选择性的记忆解决RNN长距离依赖。
- RNN被赋予对于前面内容的“记忆”能力。
- LSTM通过记忆元件解决长距离依赖问题,但它是一种前向转播算法,对于命名实体识别而言,需要综合反向的LSTM进行学习,即BiLSTM。
- 一个LSTM计算前向隐特征,另一个计算后向隐特征
- 我们把LSTM输出结果拼接,得到双向LSTM网络,用于特征提取。
- 标准Bi-LSTM输出通过SoftMax层预测节点间的分类标签。
得到P矩阵
流程:
-
将完整的隐状态序列从n维映射到k维,其中k为标注集的标签数。
-
得到自动提取的句子特征,即为,注意该矩阵为非归一化矩阵!
- 注意实为发射分数,来自BiLSTM的输出
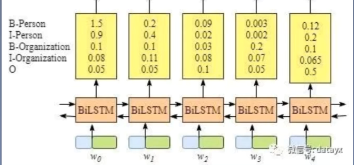
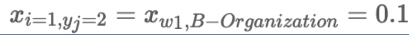
- X代表分数,其中i是单词位置的索引,yi为类别的索引
- 注意实为发射分数,来自BiLSTM的输出
-
pi代表该单词对应的各个分类的分数。
-
如最开始的图所示,黄色矩阵中的分数1.5,0.9等,这些都将作为CRF层的输入。
CRF层的引入
问题:为什么要加CRF?用标签分数最大值不可以吗?
CRF作用:NER是一类特殊的任务,表征标签的可解释序列的“语法”强加了很多约束,比如I-Person前需要有B-Person,而不是I-Organization等等。CRF层能够学习到句子前后依赖,加入约束确保预测结果有效。
注:这些标签是先验的。
转移分数:
来自CRF层可以学习到的转移矩阵,它是BiLSTM-CRF模型的一个参数,可随机初始化转移矩阵分数并在训练中更新。
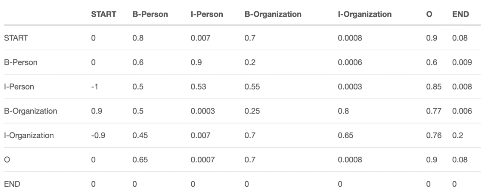
计算最终结果
CRF考虑前后标记依赖约束,综合标记状态转换概率作为评分:
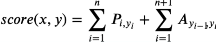
其中,前半部分为发射分数(pi),后半部分为转移分数。
路径分数:
其中:
找到一条最优的路径。
CRF损失函数与维特比解码
前向算法
概率计算问题:已知模型参数和观测序列,计算观测序列出现概率。
前向算法在NER中的作用:
-
快速计算真实路径得分与所有路径得分比值
-
预测时得到最优路径
维特比算法
一种选择最优路径的动态规划算法。从开始状态每走一步,记录到达该状态所有路径的最大概率值,最后以最大值为基准继续向后推进,到达结尾回溯最大概率,也就是最有可能的路径。
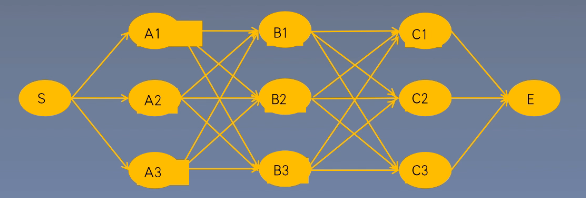
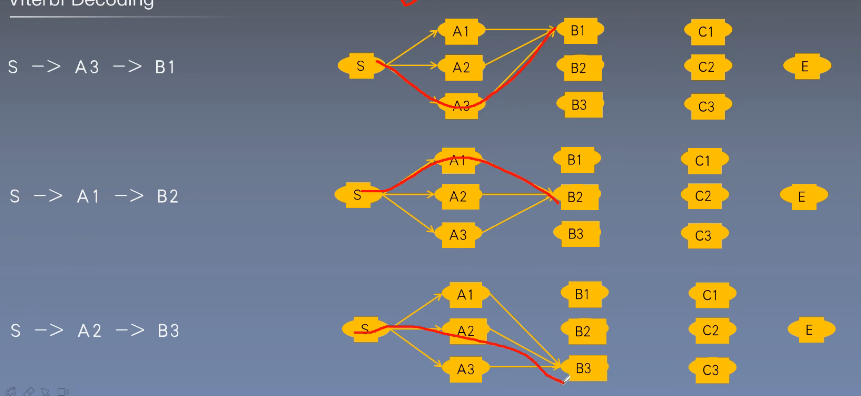
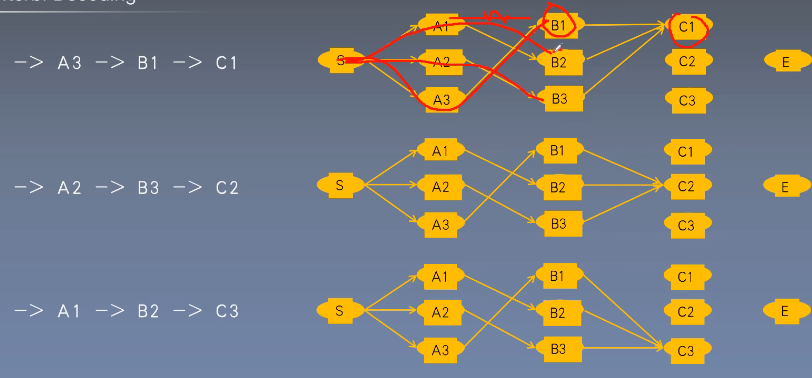
到达 后回溯找到概率最大的一条路径。
CRF损失函数
由两部分组成:真实路径分数(所有路径分数最高的)与所有路径总分数。
损失函数详细计算步骤及理解见:BiLSTM中的CRF层损失函数
论文总结
关键点
- 采用LSTM做特征抽取
- 采用CRF结构体系做标签建模
- 弱依赖外部资源和特征
创新点
- 采用双向LSTM做特征抽取
- 证明BiLSTM-CRF模型鲁棒性与对词向量的弱依赖
启发点
论文拓展
-
Neural Architectures for Named Entity Recognition
- 基于字符的词向量,对效果有明显提升
-
Named Entity Recognition with Bidrectional LSTM-CNNs
- 在表示层将词向量、词特征以及用CNN提取的字符向量与特征作为表示层。
-
NCRF++
- 神经网络版本CRF++。