原子操作
概念
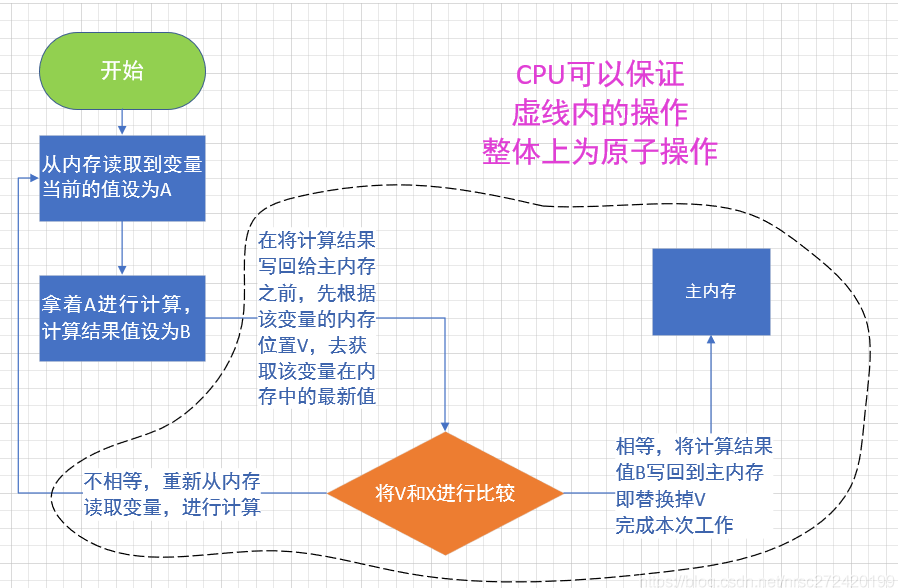
原子操作是多线程程序中"最小且不可并行化"的操作。通常对一个共享资源的操作是原子操作的话,意味着多个线程访问该资源时,有且仅有唯一一个线程在对这个资源进行操作。
通常情况下,原子操作通过"互斥"(mutual exclusive)的访问来保证。实现互斥通常需要平台相关的特殊指令,在c++11标准之前,这常常意味着需要在c/c++代码中嵌入内联汇编代码。
问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| #include <pthread.h>
#include <iostream>
using namespace std;
static long long total=0;
pthread_mutex_t m=PTHREAD_MUTEX_INITIALIZER;
void* func(void*)
{
long long i;
for(i=0;i<100000000;i++)
{
pthread_mutex_lock(&m);
total+=i;
pthread_mutex_unlock(&m);
}
}
int main()
{
pthread_t thread1,thread2;
if(pthread_create(&thread1,NULL,&func,NULL))
{
throw;
}
if(pthread_create(&thread2,NULL,&func,NULL))
{
throw;
}
pthread_join(thread1,NULL);
pthread_join(thread2,NULL);
cout<<total<<endl;
return 0;
}
|
代码中为了防止数据竞争,我们使用了pthread_mutex_t的互斥锁保证两个线程可以正确的访问total。
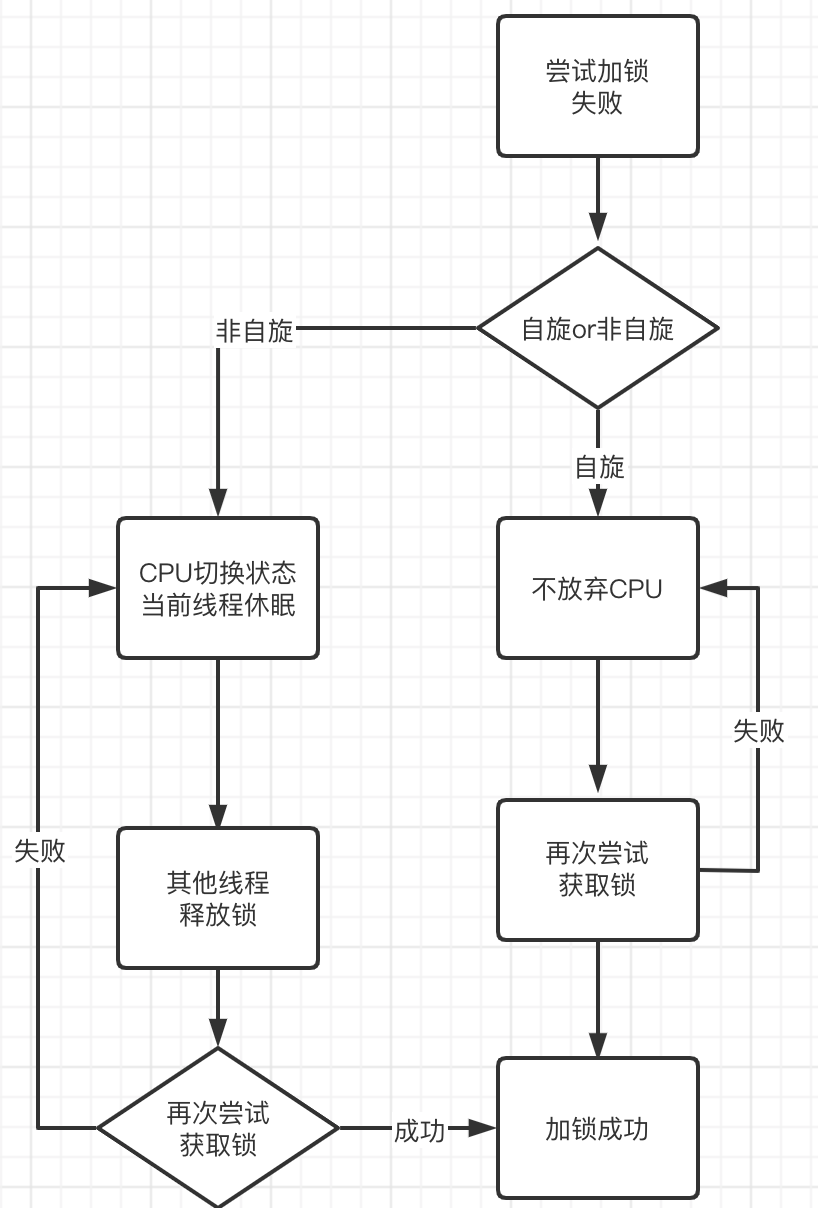
- 加锁和解锁会消耗系统资源
- 代码移植性较差,像我们实际开发过程中,一套代码中兼容windows和linux等的地方比比皆是,这其实是程序员做了"妥协"。
C++11的改进
c++11对数据进行了更加良好的抽象,引入“原子数据类型”(atomic),以达到对开发者掩盖互斥锁、临界区的目的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
#include<atomic>
#include<thread>
#include<iostream>
using namespace std;
std::atomic_llong total{ 0 };
void func(int)
{
for (long long i = 0; i<100000000; ++i)
{
total += i;
}
}
int main()
{
thread t1(func, 0);
thread t2(func, 0);
t1.join();
t2.join();
cout<<total<<endl;
return 0;
}
|
将total定义为原子类型std::atomic_llong,使得程序不需要显示的调用API来加锁、解锁,对于代码来说,即容易又简洁。
atomic
template <class T> struct atomic;
参考手册:http://cplusplus.com/reference/atomic/atomic/?kw=atomic
内存模型与memory_order
强顺序与弱顺序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| #include <iostream>
#include <atomic>
#include <iostream>
using namespace std;
atomic<int> m{0};
atomic<int> n{0};
int main()
{
int tmp = 1;
m = tmp;
n = 3;
return 0;
}
|
汇编代码如下:
1
2
3
4
5
| loadi reg3, 1; #将1放入寄存器reg3
move reg4, reg3; #将reg3的数据放入reg4
store reg4, m; #将寄存器reg4中的数据存入内存地址m
loadi reg5, 2; #将立即数2放入寄存器reg5
store reg5, n; #将寄存器5中的数据存入内存地址n
|
强顺序:指令执行顺序为1->2->3->4->5
弱顺序:执行可能的执行顺序为1->4->2->5->3(指的是执行顺序存在一定的不确定性)
优势与劣势
优势:提高指令执行性能
劣势:多线程下,可能会造成程序运行错误;
例:单例模式中经典的double check双检查锁的实现方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| Singleton* Singleton::getInstance()
{
if (m_instance == nullptr)
{
std::mutex mtx;
m_instance = new(std::nothrow) Singleton();
if (m_instance == nullptr)
{
return nullptr;
}
}
return m_instance;
}
|
默认构造顺序:分配内存、调用构造器、返回指针至instance
reorder后可能为:分配内存、指针返回值给instance、调用构造器
导致问题:当一个线程执行到第二步时,假如此时有另外一个线程访问,会默认m_instance不为空返回,此时实际还未调用构造器,进而导致不可预知的问题。
memory_order
1
2
3
4
5
6
7
8
| typedef enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
} memory_order;
|

对于单例构造的修改:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| std::atomic<Singleton*> Singleton::m_instance;
std::mutex Singleton::m_mutex;
Singleton* Singleton::getInstance()
{
Singleton* s = m_instance.load(std::memory_order_relaxed);
std::_Atomic_thread_fence(std::memory_order_acquire);
if (s == nullptr)
{
std::lock_guard<std::mutex> lock(m_mutex);
s = m_instance.load(std::memory_order_relaxed);
if (s == nullptr)
{
s = new Singleton;
std::_Atomic_thread_fence(std::memory_order_release);
m_instance.store(s, std::memory_order_relaxed);
}
}
return s;
}
|
memory_order参数的默认值是std::memory_order_seq_cst。实际上,atomic类型的其他原子操作接口都有memory_order这个参数,而且默认值都是std::memory_order_seq_cst。