CUDA Stream, CUDA Graph
CUDA Stream
CUDA Stream表示一个GPU操作队列,该队列中的操作将以添加到流中的先后顺序而依次执行。可以将一个流看做是GPU上的一个任务,不同任务可以并行执行。使用CUDA流,首先要选择一个支持设备重叠(Device Overlap)功能的设备,支持设备重叠功能的GPU能够在执行一个CUDA核函数的同时,还能在主机和设备之间执行复制数据操作。
CUDA 实现重叠数据传输原理
默认流
CUDA 中的所有设备操作(内核和数据传输)都在一个流中运行。如果没有指定流,则使用默认流(也称为“空流”)。默认流与其他流不同,因为它是关于设备上操作的同步流:在所有先前发出的操作 在设备上的任何流中 完成之前,默认流中的任何操作都不会开始,并且默认流中的操作必须在任何其他操作(在设备上的任何流中)之前完成就要开始了。
关于内核从主机的角度启动的异步行为使得重叠设备和主机的计算如下所示:
1 | cudaMemcpy(d_a, a, numBytes, cudaMemcpyHostToDevice); |
非默认流
CUDA C++中流可以被创建与销毁:
1 | cudaStream_t stream1; |
为了向非默认流发出数据传输,我们使用了 cudaMemcpyAsync() 函数:
1 | result = cudaMemcpyAsync(d_a, a, N, cudaMemcpyHostToDevice, stream1) |
流同步
注意:这个函数是非阻塞的!需要与流进行同步!
cudaDeviceSynchronize() ,它会阻止主机代码,直到之前在设备上发出的所有操作都完成为止。性能浪费!
cudaStreamSynchronize(stream) 可用于阻止主机线程,直到指定流中以前发出的所有操作都已完成。
cudaStreamQuery(stream) 测试向指定流发出的所有操作是否已完成,而不阻止主机执行。
cudaEventSynchronize(event) 和 cudaEventQuery(event) 的行为与它们的流对应项相似,只是它们的结果基于是否记录了指定的事件,而不是基于指定的流是否空闲。
cudaStreamWaitEvent(event)在单个流中同步特定事件的操作(即使事件记录在不同的流中,或者记录在不同的设备上)。
重叠的内核执行和数据传输
修改前的主机代码如下所示:
1 | cudaMemcpy(d_a, a, numBytes, cudaMemcpyHostToDevice); |
准备探寻是否可以实现流同步:
方法一:
1 | for (int i = 0; i < nStreams; ++i) { |
方法二:
1 | for (int i = 0; i < nStreams; ++i) { |
这两种方法在不同设备执行时间是并不同的(甚至存在负优化的情况!)这是因为有的设备(C1060)只有一个拷贝引擎,这使得内存交换与运算可能无法掩盖;有的有两个复制引擎,一个用于主机到设备的传输,另一个用于设备到主机的传输。但在以上两种情况下性能又是不一样。具体见Reference[1]。
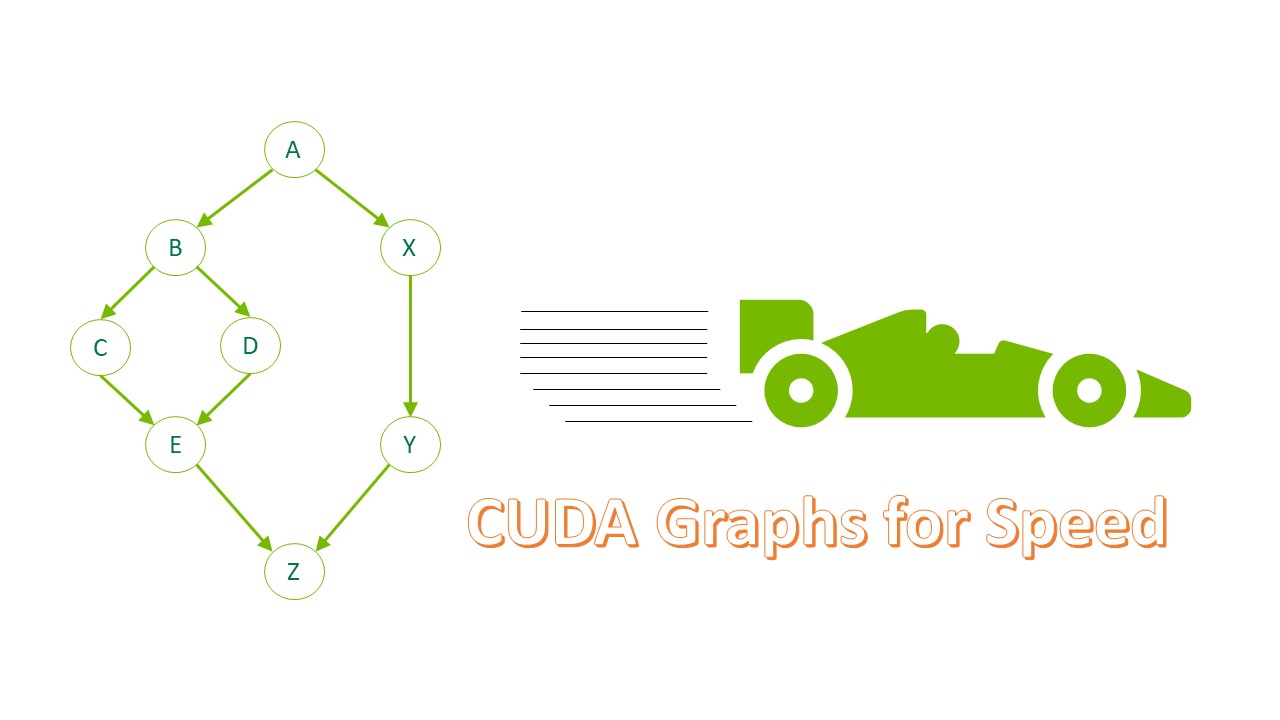
CUDA Graph
应用程序中可能存在一些小的、执行次数较多的kernel,多次启动、释放资源的开销往往导致程序整体性能较差。CUDA Graphs 将整个计算流程定义为一个图而不是单个操作的列表。 最后通过提供一种由单个 CPU 操作来启动图上的多个 GPU 操作的方式减少kernel提交启动开销,进而解决上述问题。
简单程序的优化流程(kernel执行时间:2.9μs):
-
baseline:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// start CPU wallclock timer
for(int istep=0; istep<NSTEP; istep++){
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(out_d, in_d);
cudaStreamSynchronize(stream);
}
}
//end CPU wallclock time
// Kernel average time: 9.6μs
// 每次执行完都要调用同步,启动、释放开销完全暴露 -
Overlapping
1
2
3
4
5
6
7
8
9
10
11// start wallclock timer
for(int istep=0; istep<NSTEP; istep++){
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(out_d, in_d);
}
cudaStreamSynchronize(stream);
}
//end wallclock timer
// Kernel average time: 3.8μs
// 不需要每次同步,kernel之间调用是异步的,可以掩盖启动时间。但仍然存在与多次启动相关的开销,外层循环的同步时间是一定存在的。 -
CUDA Graph
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20bool graphCreated=false;
cudaGraph_t graph;
cudaGraphExec_t instance;
for(int istep=0; istep<NSTEP; istep++){
if(!graphCreated){
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
for(int ikrnl=0; ikrnl<NKERNEL; ikrnl++){
shortKernel<<<blocks, threads, 0, stream>>>(out_d, in_d);
}
cudaStreamEndCapture(stream, &graph);
cudaGraphInstantiate(&instance, graph, NULL, NULL, 0);
graphCreated=true;
}
cudaGraphLaunch(instance, stream);
cudaStreamSynchronize(stream);
}
// Kernel average time: 3.4μs
// kernel graph只需要捕获和实例化一次,并在所有后续循环中重复使用相同的实例
// 创建实例图时间开销较大,通常为了从cuda graph中受益,需要重复调用相同的cuda graph足够多次。
动态环境中使用 CUDA 图
在 ToolkitVersion10 中引入 CUDA 图形时,可以对其进行更新,以反映其实例化中的一些细微变化。此后,此类更新操作的覆盖范围和效率显著提高。在这篇文章中,我描述了一些通过使用 CUDA 图来提高实际应用程序性能的场景,其中一些场景包括图更新功能。
具体见文章:在动态环境中使用 CUDA 图 - NVIDIA 技术博客,仅仅做初步的阅读,还没有深入思考。
Reference
[1] 如何在 CUDA C/C++ 中实现数据传输的重叠 - NVIDIA 技术博客
[2] Getting Started with CUDA Graphs | NVIDIA Technical Blog