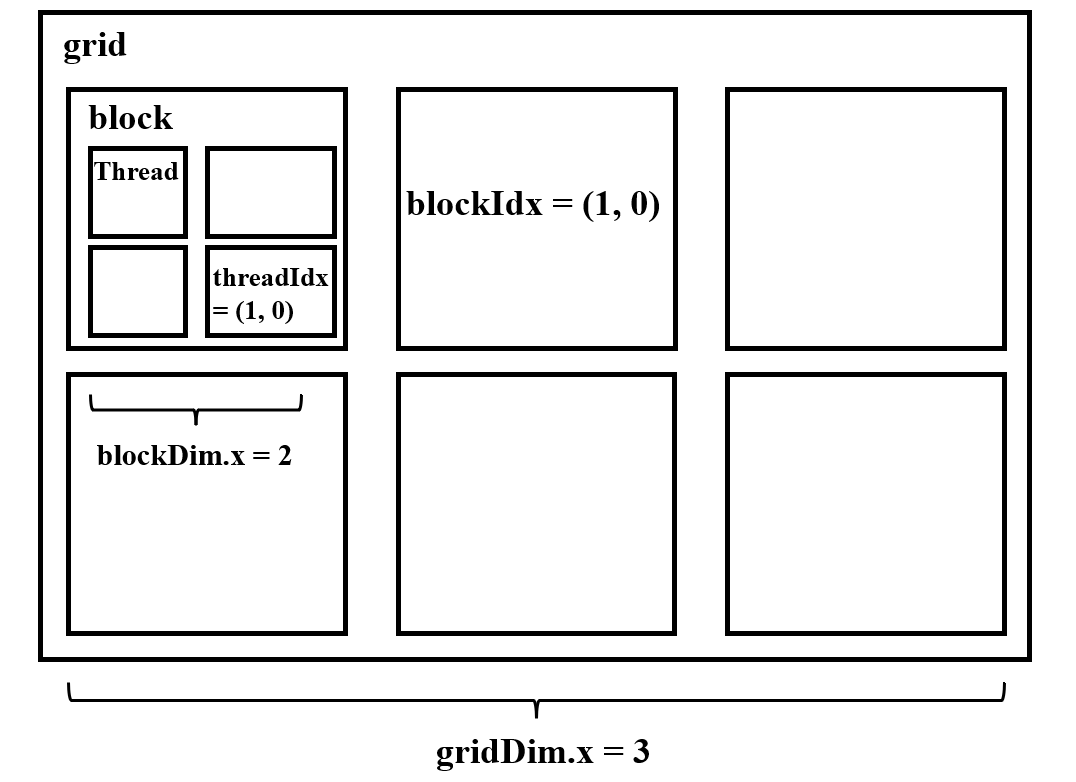
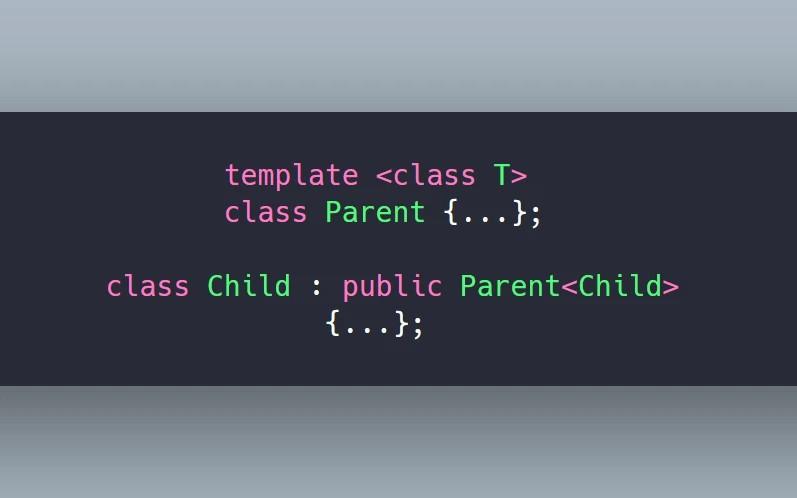
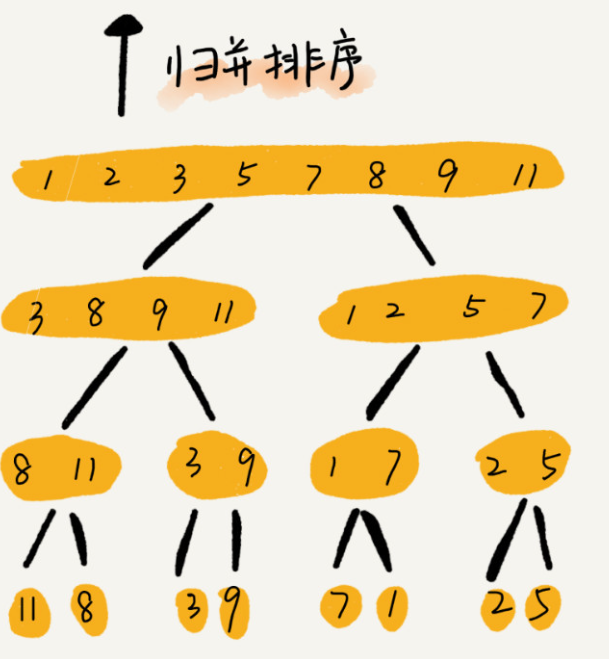
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
|
#include "kernel.cuh"
#include <stdio.h>
#include <cmath>
#include <iostream>
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
const int blocksPerGrid = imin(32, (N + threadsPerBlock - 1) / threadsPerBlock);
bool float_equal(float a, float b) {
if (std::abs(a - b) < 1e1) return true;
return false;
}
int main()
{
float* a, * b, c = 0, * partial_c;
float* dev_a, * dev_b, * dev_partial_c;
a = new float[N];
b = new float[N];
partial_c = new float[blocksPerGrid];
cudaMalloc((void**)&dev_a, N * sizeof(float));
cudaMalloc((void**)&dev_b, N * sizeof(float));
cudaMalloc((void**)&dev_partial_c, blocksPerGrid * sizeof(float));
for (int i = 0; i < N; i++) {
a[i] = i;
b[i] = i * 2;
}
cudaMemcpy(dev_a, a, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N * sizeof(float), cudaMemcpyHostToDevice);
vector_add << <blocksPerGrid, threadsPerBlock >> > (dev_a, dev_b, dev_partial_c);
cudaMemcpy(partial_c, dev_partial_c, blocksPerGrid * sizeof(float), cudaMemcpyDeviceToHost);
for (int i = 0; i < blocksPerGrid; i++) {
c += partial_c[i];
}
double result = 0;
float* res_p = new float[blocksPerGrid];
for (int i = 0; i < N; i++) {
if (i == 368) {
printf("");
}
float temp = a[i] * b[i];
result = result + temp;
}
for (int i = 0; i < blocksPerGrid; i++) {
res_p[i] = 0;
for (int j = 0; j < threadsPerBlock; j++) {
res_p[i] += a[i * threadsPerBlock + j] * b[i * threadsPerBlock + j];
}
}
if (float_equal(result, c)) {
std::cout << "Test pass." << std::endl;
}
else {
std::cout << "Test error. CPU: " << result << ", GPU: " << c << std::endl;
}
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_partial_c);
free(a);
free(b);
free(partial_c);
return 0;
}
#ifndef _KERNEL_CUH_
#define _KERNEL_CUH_
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#define imin(a,b) (a<b?a:b)
const int threadsPerBlock = 256;
const int N = 33 * 1024;
__global__ void vector_add(float* a, float* b, float* c);
#endif
#include <cstdio>
#include "kernel.cuh"
extern void __syncthreads();
__global__ void vector_add(float* a, float* b, float* c) {
__shared__ float res[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int res_idx = threadIdx.x;
float temp = 0;
while (tid < N) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
res[res_idx] = temp;
__syncthreads();
int i = blockDim.x / 2;
while (i != 0) {
if (res_idx < i) {
res[res_idx] += res[res_idx + i];
}
__syncthreads();
i = i / 2;
}
if (res_idx == 0) {
c[blockIdx.x] = res[0];
}
}
|