理解CUDA并行机制--以Reduce为例
CUDA Reduce Optimization
Start from Kernal 3: Sequential Addressing
1 | __global__ void reduce(int* g_idata, int* g_odata) { |
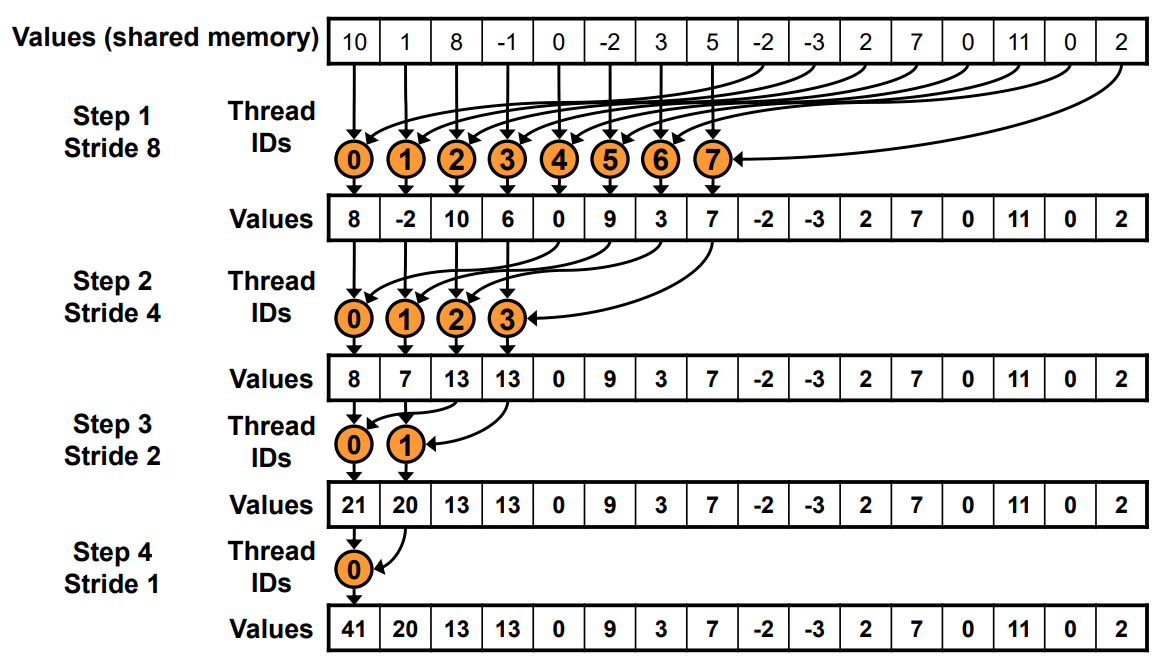
Half of threads is idle during reduce, so we want to halve the number of blocks and replace single load like this(kernal 4):
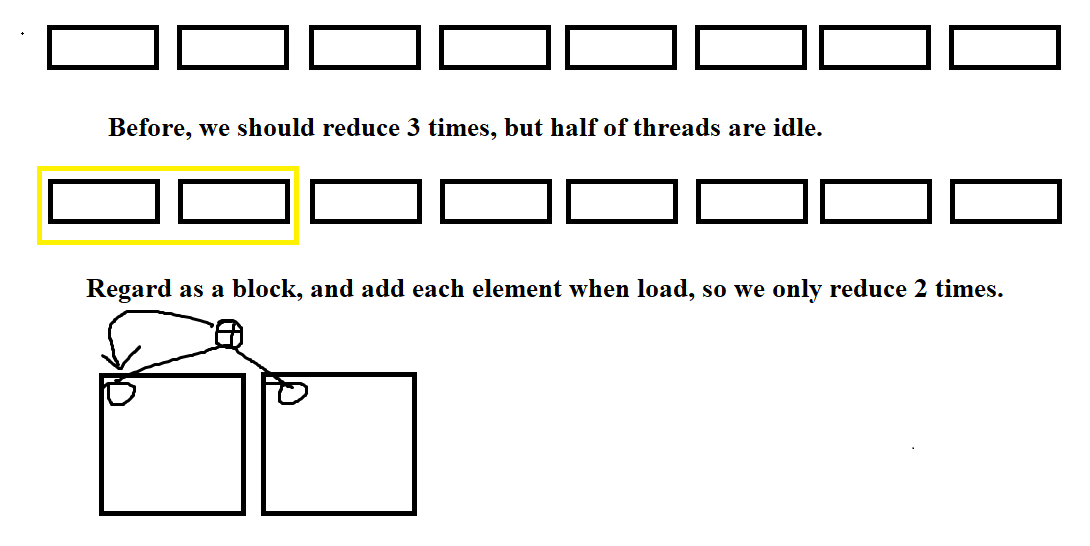
1 | unsigned int tid = threadIdx.x; |
Instructions are SIMD synchronous within a warp, so when s <= 32, we can unroll the last warp(kernal 5):
1 | __device__ void warpReduce(volatile int* sdata, int tid) { |
1 | for (unsigned int s=blockDim.x/2; s>32; s>>=1) { |
it uses the mechanism of warp, we will talk about it in the next chapter.
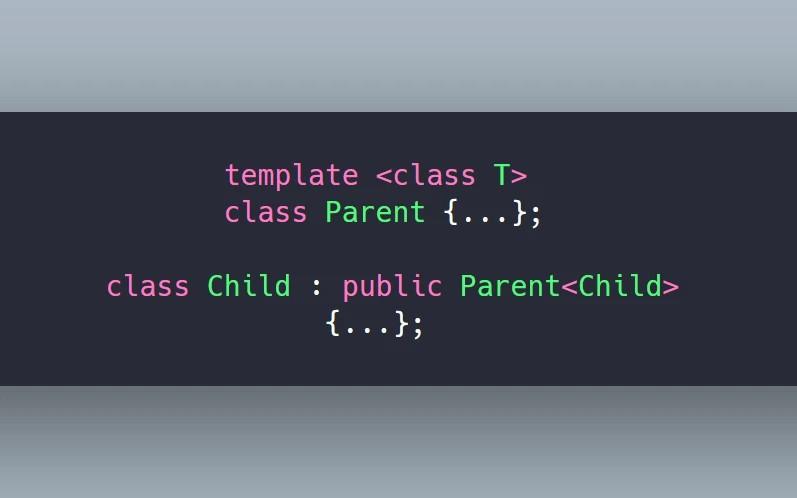
When we consider the blockSize, we know that the max number of threads is 1024. So we can completely unroll the loop when compiling. (Using template is a trick to ensure the num of threads.)(kernel 6)
1 | template <unsigned int blockSize> |
Grid, block, thread and warp in CUDA
From a hardware perspective:
- SP(streaming processor): CUDA core. A thread executes on a SP.
- SM(streaming multiprocessor): One SM has multiple SPs and has SFU, shared memory, register file and warp scheduler.
Form a software perspective:
-
thread: a CUDA program has been executed with many threads.
-
block: many threads are grouped into a block. Threads in the same block can call __syncthreads() to synchronize, also, they can use shared_memory to communicate.
-
grid: many blocks are grouped into a grid.
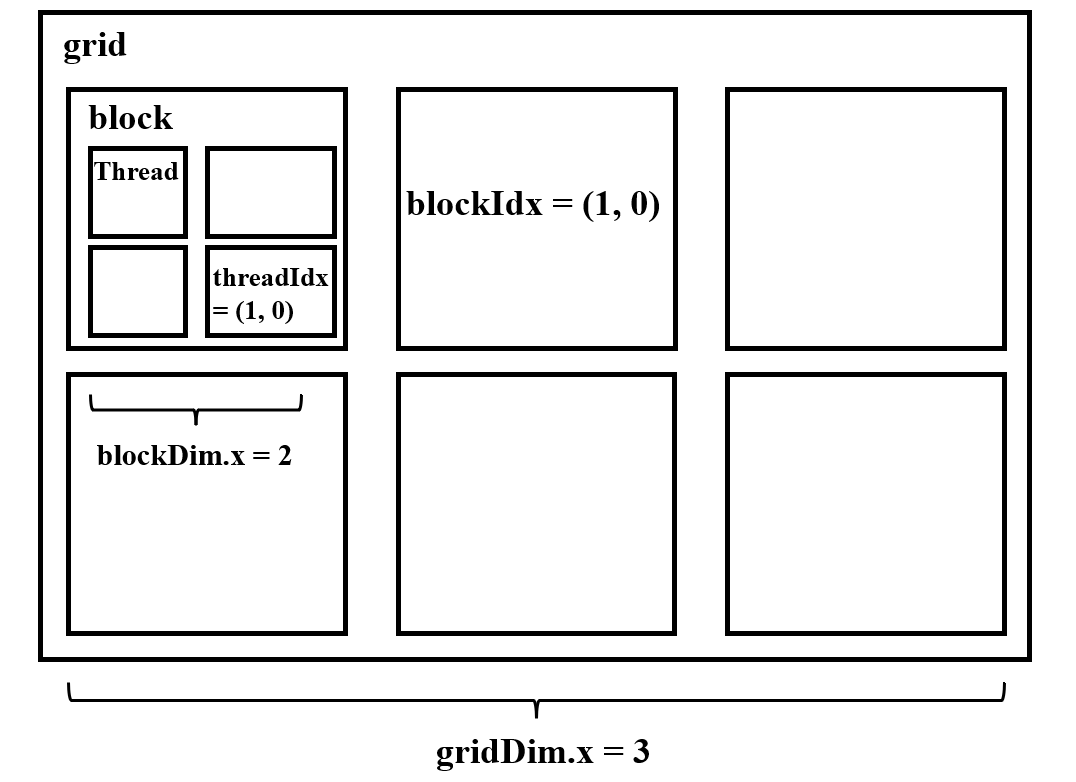
Warp:
SPs in SM are divided into many groups(warps), every warp has 32 threads(SP), and SPs in the same warp work together, execute the same instuctions.
Every thread has its own register and local memory.
Reference
CUDA编程:深入理解GPU中的并行机制(八) - 知乎 (zhihu.com)
理解CUDA中的thread,block,grid和warp - 知乎 (zhihu.com)
CUDA 学习(一)Reduction - 知乎 (zhihu.com)
GPU概念:Thread, Block, Grid, Warp, SP, SM_gpu wrap_Kevyn7的博客-CSDN博客